
This page explains some things I think beginner programmers could use to know about Unicode, text encodings, and so on.
Computers store text as bytes. There are many old “1 byte = 1 character” encodings, like ISO-8859-1 and Windows-1251.
Unicode is a project to assign universal numbers to all characters humans use across the world to write text.
UTF-8 and UTF-16 are encodings: different ways to turn Unicode numbers into bytes.
As a programmer, you should:
As you know, computers store data in "bits": ones and zeros.
To store numbers, we group these bits together, commonly into 8-bit bytes, so that we can count in binary:
00000000 = 000000001 = 100000010 = 2
…11111111 = 255
Programmers like to use hexadecimal notation for bytes, like ff for 255. I'll do that in this article, but you don't need to think about converting it to decimal or binary: just know that 78 9a bc is notation for some bytes.
Our modern 64-bit processors operate on "words" of 8 bytes at a time, to calculate with even bigger numbers. But the smallest "addressable unit" is still a byte. We can't store a file or transmit a buffer that's half a byte long, for example.
To store text, a computer needs to decide on some "code" or "encoding": a correspondence between characters (letters, digits, punctuation, spaces…) and groups of bits.
Actually, people have been solving this problem for longer than the 8-bit byte has been standardized. Here is a 5-bit code used for telegraphs:
Here is a 7-bit code that got pretty popular:
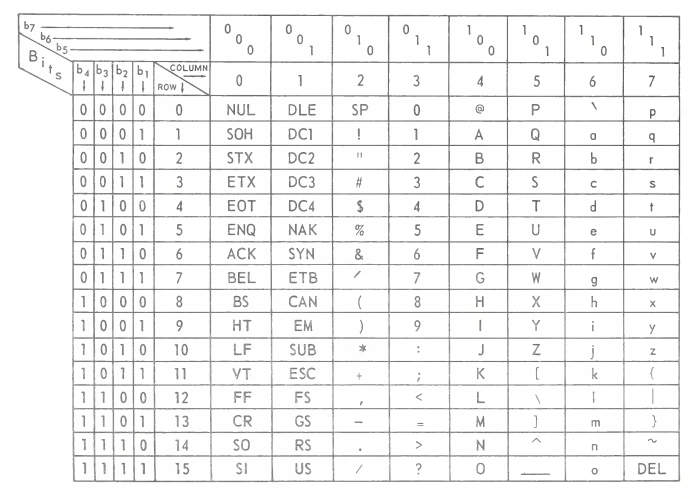
This code, ASCII, forms the basis of many encodings of text still in use today.
ASCII is a 7-bit code, so when storing it in 8-bit bytes, the highest bit is unused. One thing we could do with it is assign 128 more characters to all the 1xxxxxxx bytes and write more languages than just English!
A lot of people did this, giving rise to many 8-bit character encodings.
••••••••••••••••
••••••••••••••••
•!"#$%&'()*+,-./
0123456789:;<=>?
@ABCDEFGHIJKLMNO
PQRSTUVWXYZ[\]^_
`abcdefghijklmno
pqrstuvwxyz{|}~•
ΑΒΓΔΕΖΗΘΙΚΛΜΝΞΟΠ
ΡΣΤΥΦΧΨΩαβγδεζηθ
ικλμνξοπρσςτυφχψ
░▒▓│┤╡╢╖╕╣║╗╝╜╛┐
└┴┬├─┼╞╟╚╔╩╦╠═╬╧
╨╤╥╙╘╒╓╫╪┘┌█▄▌▐▀
ωάέήϊίόύϋώΆΈΉΊΌΎ
Ώ±≥≤ΪΫ÷≈°∙·√ⁿ²■•
Like Greek!
(MS-DOS CP737)
••••••••••••••••
••••••••••••••••
•!"#$%&'()*+,-./
0123456789:;<=>?
@ABCDEFGHIJKLMNO
PQRSTUVWXYZ[\]^_
`abcdefghijklmno
pqrstuvwxyz{|}~•
ЂЃ‚ѓ„…†‡€‰Љ‹ЊЌЋЏ
ђ‘’“”•–—•™љ›њќћџ
•ЎўЈ¤Ґ¦§Ё©Є«¬®Ї
°±Ііґµ¶·ё№є»јЅѕї
АБВГДЕЖЗИЙКЛМНОП
РСТУФХЦЧШЩЪЫЬЭЮЯ
абвгдежзийклмноп
рстуфхцчшщъыьэюя
Or Russian!
(Windows-1251)
••••••••••••••••
••••••••••••••••
•!"#$%&'()*+,-./
0123456789:;<=>?
@ABCDEFGHIJKLMNO
PQRSTUVWXYZ[\]^_
`abcdefghijklmno
pqrstuvwxyz{|}~•
ÄÅÇÉÑÖÜáàâäãåçéè
êëíìîïñóòôöõúùûü
Ý°¢£§•¶ß®©™´¨≠ÆØ
∞±≤≥¥µ∂∑∏π∫ªºΩæø
¿¡¬√ƒ≈∆«»…•ÀÃÕŒœ
–—“”‘’÷◊ÿŸ⁄€ÐðÞþ
ý·‚„‰ÂÊÁËÈÍÎÏÌÓÔ
ÒÚÛÙıˆ˜¯˘˙˚¸˝˛ˇ
Or Icelandic!
(Mac OS Icelandic)
But wouldn't it be nice if there was one universal standard? How am I going to write a Greek–Russian dictionary?
Unicode is essentially a project to assign a universal number to every character humans ever use to write text.
| G | 71 |
| न | 2,344 |
| ⊈ | 8,840 |
| 字 | 23,383 |
| 🌴 | 127,796 |
These numbers are called code points.
Unicode itself is not a character encoding: it only says 字 has code point number 23383, but not how to encode that number as bytes in a text file.
Code point numbers go up to 1,114,111, or 10ffff in hexadecimal. So we can't fit them in a single byte, and some code points will have to be represented by multiple bytes.
There are various ways to turn code points into byte streams. The famous ones are UTF-32, UTF-16, and UTF-8. Each is a little more complex, more compact, and more widely used than the last.
We can definitely store any codepoint if we use four bytes (32 bits) per character:
00000048 | 00000069 | 00004f60 | 0000597d | 0001f680 |
| H | i | 你 | 好 | 🚀 |
This is really wasteful: we only need 21 bits to count up to 10ffff, so we're always going to be storing a lot of unnecessary 0 bits.
Something like “UTF-24” or “UTF-21” would be less wasterful. But our computers are especially good at handling data that's aligned to 32 bits, which is why UTF-32 is used instead.
We can see most characters actually fit in 16 bits: in the example above, the rocket emoji is the only one that wouldn't. In fact, almost every codepoint between 20000 and 10ffff is unassigned as of 2022.
Here's an idea: use 16 bits for most codepoints, and represent those beyond ffff using two special 16-bit units.
Actually, Unicode assigns special codepoints for this exact purpose. They are called surrogates.
The range of code points d800 and dfff is reserved for use in UTF-16 text. They always occur in pairs, and work together to encode a larger code point.
0048 | 0069 | 4f60 | 597d | d83d de80 |
| H | i | 你 | 好 | 🚀 |
JavaScript strings use UTF-16. Try opening the JavaScript console on this page (Ctrl+Shift+J or ⌘⌥J) and writing:
"🚀".lengthThe result is 2, because .length counts the number of UTF-16 "code units", and the rocket emoji is made up of two surrogates.
Another thing to look out for is indexing: you'll get only one surrogate character, instead of the full rocket.
"Hello🚀"[5]You have to slice out two units to get the rocket character.
"Hello🚀".slice(5, 7)A nice trick in JavaScript is to write [...string], which gets an array of all the characters in a string, whether they are 1 or 2 units in UTF-16.
[..."Hello🚀"]This is the most widely used Unicode encoding. This webpage uses UTF-8!
The idea is to use bytes 00 through 7f for codepoints 0 through 127, and sequences of higher bytes for other characters.
48 | 69 | e4bda0 | e5a5bd | f09f9a80 |
| H | i | 你 | 好 | 🚀 |
Upside: Unicode codepoints 0 through 127 correspond exactly with ASCII! So ASCII strings are automatically valid UTF-8 strings.
Up-or-downside: This is more compact for Latin-alphabet text and source code. But it's less compact for Hindi or Chinese text, for example.
Downside: it's even harder to find the length of a string or get the character at some index. (But UTF-16 and its “surrogates” have this problem too.)
Upside: it's "self-synchronizing" — if you start reading at the wrong index, you will eventually get correct characters again.
If you miss the first byte of a UTF-16 stream, you'll decode garbage forever:
| Original text | 你 | 在 | 做 | 什 | 么 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| UTF-16 | 4f | 60 | 57 | 28 | 50 | 5a | 4e | c0 | 4e | 48 |
| Misaligned decode | 恗 | ⡐ | 婎 | 쁎 | … | |||||
But UTF-8 separates "continuation bytes" from "start bytes", so if you miss the first byte of a UTF-8 stream, you'll eventually recover.
| Original | 你 | 在 | 做 | 什 | 么 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UTF-8 | e4 | bd | a0 | e5 | 9c | a8 | e5 | 81 | 9a | e4 | bb | 80 | e4 | b9 | 88 |
| Bad decode | � | � | 在 | 做 | 什 | 么 | |||||||||